Anonymous and Aggregated Subscriber Data
If you haven’t yet heard the term anonymous and aggregated subscriber data, allow us to introduce you to the future.
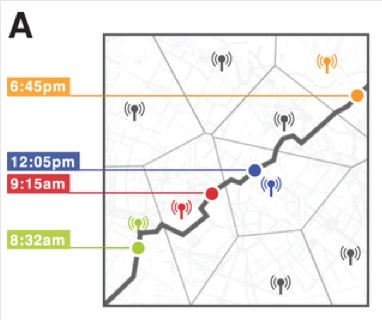
Simply put, “subscriber data” is information collected from your cell phone as you move about the day. How long is your commute? Do you take surface streets or the highway? What stores do you shop at? What apps do you use? How often?
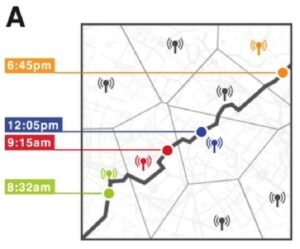 Anonymous and aggregated subscriber data is all of that information, for every subscriber to a given cell phone service provider (Verizon Wireless, for example), accumulated and randomized to protect individual privacy. As a whole, it can give tremendously detailed pictures of traffic flows, population demographics and consumer groups of a given area or city. Anonymous and aggregated subscriber data (AASD) is highly sought after, and hotly contentious.
Anonymous and aggregated subscriber data is all of that information, for every subscriber to a given cell phone service provider (Verizon Wireless, for example), accumulated and randomized to protect individual privacy. As a whole, it can give tremendously detailed pictures of traffic flows, population demographics and consumer groups of a given area or city. Anonymous and aggregated subscriber data (AASD) is highly sought after, and hotly contentious.
AASD, or Mobility Data as it is often called, is like analytic data for an organization’s website, but for real people walking and driving around in the real world. It can provide all kinds of information, without costly surveys or interviews. Say a city invests in a new rail system – in the months after its implementation, an AASD report could tell city officials how many individuals stopped driving to work and started taking the train. Park Departments could track how many people visit a new facility, what their cultural demographics are, and how far they traveled to get there. Employers could theoretically know if a “sick” employee showed up at a Dodger game.
The possibilities are tremendous. In late 2011, Verison Wireless changed its privacy policy so that it could share anonymous and aggregated subscriber data and launched its Precision Market Insights division in October of 2012. Likewise, a few innovative companies, like San Francisco-based StreetLight and AirSage in Atlanta, are positioning themselves to cash in.
The data being collected is similar to the information that has been culled by the California Metropolitan Transportation Commission for years. Anyone driving around with a FasTrack toll tag is transmitting data to a central system to “provide better information about the transportation network.” While FasTrack explains that the first step taken with the data is to scramble the individual ID numbers to protect privacy, some consumers are skeptical, and for good reason.
A study done at Cornell University found that it was actually quite easy to cross reference anonymous and aggregated data to figure out exactly which individuals correlated to what data points:
We apply our de-anonymization methodology to the Netflix Prize dataset, which contains anonymous movie ratings of 500,000 subscribers of Netflix, the world’s largest online movie rental service. We demonstrate that an adversary who knows only a little bit about an individual subscriber can easily identify this subscriber’s record in the dataset. Using the Internet Movie Database as the source of background knowledge, we successfully identified the Netflix records of known users, uncovering their apparent political preferences and other potentially sensitive information.
Another study, completed by a team of researchers from Louvain University in Belgium, Harvard and MIT, found that Mobility Data is “among the most sensitive data currently being collected.” Their report, titled “Unique in the Crowd: The privacy bounds of human mobility,” went on to say:
…in a dataset where the location of an individual is specified hourly, and with a spatial resolution equal to that given by the carrier’s antennas, four spatio-temporal points are enough to uniquely identify 95% of the individuals…even coarse datasets provide little anonymity.
The threat of hackers mining for personal information will always be present with this sort of data usage, but the potential for positive impact is too great to ignore.
The implications of this, as we go about our lives with transmitters in our pockets or purses, have yet to be fully realized, but there’s no doubt that, as technologies progress, we will be hearing more about anonymous and aggregated subscriber data.